
Deep learning 모델 등 차세대 컴퓨팅 문제를 해결하기 위한 AI 가속 칩을 개발중인 Cerebras가 발표한 세계에서 가장 큰 실리콘 칩인 '웨이퍼 스케일 엔진(Wafer Scale Engine)' 기반으로 만든 AI 가속 칩 'Cerebras CS-1'을 출시했다.

Cerebras CS-1의 'CS-1'칩은 1조 2천억 개의 트랜지스터로 구성되며 100Pbit/s 병렬로 연결된 400,000개의 AI 최적화 코어와 전례없는 9PB/s의 메모리 대역폭과 함께 18GB의 초고속 온칩 메모리로 구성되어있습니다.
이를 구동하기 위한 시스템은 12기가비트 이더넷 연결 CS-1 데이터 이동 시스템 등 CS-1 프로세서를 운영하고 데이터 센터에 통합하는 데 필요한 모든 냉각, 네트워킹, 스토리지 및 기타 장비가 포함됩니다. 전력은 20 킬로와트 급이다.
셀레브라스는 CS-1이 GPU 1,000개 이상의 성능을 제공한다고 주장하고 있습니다.


개발자가 텐서플로(TensorFlow) 및 파이토치(PyTorch) 등 인기있는 ML 라이브러리를 사용해 AI 워크플로를 CS-1 시스템과 통합할 수 있는 포괄적 소프트웨어 플랫폼 (Software Development Kit, SDK)을 제공합니다.
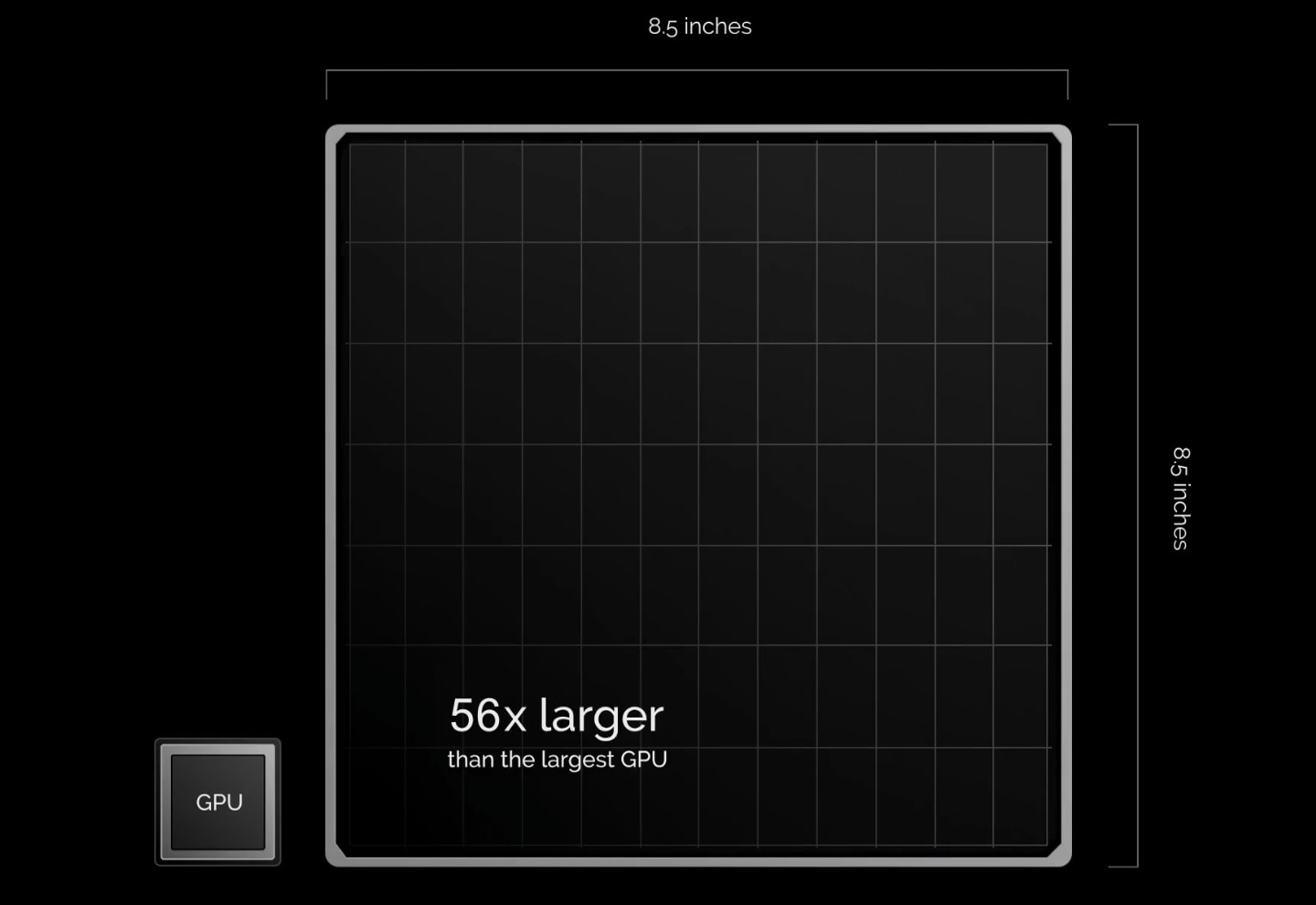
필자가 "CPU & GPU칩을 무식하게 크기 늘리면 성능 개 쩔텐데를 구현"이라고 표현한 이유는
Cerebras CS-1 칩은 아이패드 크기로 AI 가속에 사용되는 엔비디아(Nvidia) GPU 보다 수십배 크다는 점 때문입니다.
사실상 Cerebras CS-1은 이러한 거대한 칩에 더 많은 트랜지스터와 AI 최적화 코어, 메모리를 때려 박는 방식으로 무식하게(?) 성능을 끌어올린 결과물입니다.

테크크런치에 따르면 앤드류 펠트만(Andrew Feldman) CEO는 웨이퍼 규모 칩이 작은 칩에 비해 “국소성을 활용해 의사소통 시간을 크게 줄였다”고 말했습니다. 설명에 따르면 컴퓨터 과학에서 국소성은 지연과 처리 마찰을 최소화하는 클라우드 내에서 적절한 장소에 데이터를 배치하고 계산한다. 이론적으로 전체 ML 모델을 호스팅 할 수 있는 칩을 사용하면 데이터가 여러 스토리지 클러스터 또는 이더넷 케이블을 통해 흐를 필요가 없다. 칩이 작동하는 데 필요한 모든 자원을 거의 즉시 활용할 수 있다.